

- 10 Mar
- 2026
Cross-Project Software Effort Estimation Pendekatan Transfer Learning Menggunakan Machine Learning dan Optuna Hyperparameter Optimization
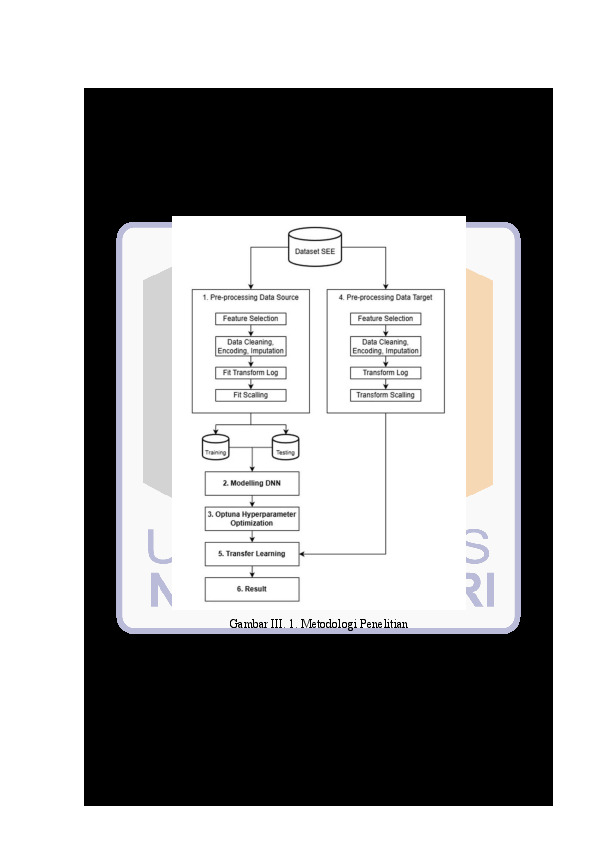
Perkiraan upaya pengembangan perangkat lunak yang akurat tetap menjadi tantangan kritis dalam rekayasa perangkat lunak, terutama dalam skenario lintas perusahaan atau lintas dataset di mana heterogenitas data dalam fitur, skala, dan distribusi menurunkan kinerja model prediksi tradisional. Studi ini menyelidiki penerapan kerangka kerja Heterogeneous Transfer Learning (HTL) berbasis Deep Neural Network (DNN) untuk meningkatkan akurasi perkiraan upaya di seluruh dataset heterogen.
Pendekatan yang diusulkan dimulai dengan identifikasi dan penyelarasan semantik fitur-fitur umum dari lima dataset yang tersedia secara publik: China, NASA93, Desharnais, Maxwell, dan SEERA. Pra-pemrosesan data meliputi transformasi Log1p untuk mengurangi kemiringan, pembersihan data, dan imputasi. Model DNN dasar dilatih pada dataset China dan dioptimalkan menggunakan Optuna untuk penyesuaian hiperparameter. Model yang dioptimalkan kemudian digunakan sebagai model sumber yang telah dilatih sebelumnya dalam eksperimen transfer learning, di mana berbagai strategi adaptasi dievaluasi dengan mengubah pembekuan dan pembukaan lapisan tersembunyi, mulai dari pembekuan penuh hingga penyesuaian penuh.
Hasil eksperimen menunjukkan bahwa efektivitas kerangka kerja HTL sangat bergantung pada kesesuaian antara strategi adaptasi dan karakteristik dataset target. Peningkatan kinerja yang signifikan diamati pada NASA93 (R² meningkat dari 0,20 menjadi 0,56) dan SEERA (R² mencapai 0,9173 pada fine-tuning penuh). Dataset Maxwell menunjukkan kompatibilitas tinggi, mencapai R² 0,85 bahkan dengan representasi yang dibekukan. Sebaliknya, Desharnais tetap menantang, dengan nilai R² yang rendah secara konsisten (0,16), menunjukkan kesenjangan domain yang ekstrem. Temuan ini mengonfirmasi kelayakan transfer learning heterogen untuk estimasi upaya perangkat lunak lintas dataset dan menyoroti bahwa tidak ada strategi fine-tuning universal yang ada. Sebaliknya, kedalaman adaptasi harus disesuaikan dengan tingkat heterogenitas setiap domain target, memberikan wawasan praktis untuk mengembangkan model estimasi upaya yang lebih robust dan generalisable.
Unduhan



-

-

-

JJEE MS WORD TEMPLATE FOR ARTICLES' PREPARATION_Manuskrip-HTL-SEE.pdf
Terakhir download 26 Jul 2026 02:07FIle_8_draft_manuskrip
- diunduh 0x | Ukuran 783,339
-

FIle_1_cover,pernyataan,pengesahan,bimbingan,abstrak,daftarpustaka.pdf
Terakhir download 17 Jul 2026 04:07FIle_1_cover,pernyataan,pengesahan,bimbingan,abstrak,daftarpustaka
- diunduh 33x | Ukuran 1,049,772
-

FIle Tesis full-repository.pdf
Terakhir download 26 Jul 2026 02:07Full Tesis
- diunduh 0x | Ukuran 1,511,380
REFERENSI
[1] G. Silberschatz, A., Galvin, P. B., & Gagne, Operating system concepts (10th ed.), 10th ed. Laurie Rosatone, 2018. [Online]. Available: https://os.ecci.ucr.ac.cr/slides/Abraham-Silberschatz-Operating-System-Concepts-10th-2018.pdf
[2] A. Jadhav, S. K. Shandilya, I. Izonin, and R. Muzyka, “Multi-Step Dynamic Ensemble Selection to Estimate Software Effort,” Appl. Artif. Intell., 2024, doi: 10.1080/08839514.2024.2351718.
[3] K. Lavingia, V. Patel, and A. Lavingia, “Software Effort Estimation using Machine Learning Algorithms,” Scalable Comput. Pract. Exp., vol. 25, no. 2, pp. 1276–1285, 2024, doi: 10.12694/scpe.v25i2.2213.
[4] T. M. K. Kumar and M. A. Jayaram, “Software Effort Estimation Using Hard Limiting Techniques with Special Reference to Small Size Technical &Analytical Projects,” in International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT), Mandya, India: IEEE Fourth International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT), 2022, pp. 1–8. doi: 10.1109/ICERECT56837.2022.10060696.
[5] D. M. Singh and D. R. Tripathi, “Traditional and recent techniques of effort estimation in software engineering,” BSSS J. Comput., 2023, doi: 10.51767/jc1403.
[6] farah alhamdany and L. Ibrahim, “Software Development Effort Estimation Techniques: A Survey,” مجلة التربية والعلم, vol. 31, no. 1, pp. 80–92, 2022, doi: 10.33899/edusj.2022.132274.1201.
[7] M. Jorgensen and M. Shepperd, “A Systematic Review of Software Development Cost Estimation Studies,” IEEE Trans. Softw. Eng., vol. 33, no. 1, pp. 33–53, 2007, doi: 10.1109/TSE.2007.256943.
[8] J. Wen, S. Li, Z. Lin, Y. Hu, and C. Huang, “Systematic literature review of machine learning based software development effort estimation models,” Inf. Softw. Technol., vol. 54, no. 1, pp. 41–59, Jan. 2012, doi: 10.1016/j.infsof.2011.09.002.
[9] S. W. I. Kuan, “Factors on Software Effort Estimation,” Int. J. Softw. Eng. Appl., vol. 8, no. 1, pp. 23–32, 2017, doi: 10.5121/IJSEA.2017.8103.
[10] M. Padmaja and D. Haritha, “Software Effort Estimation Using Grey Relational Analysis,” Int. J. Inf. Technol. Comput. Sci., vol. 9, no. 5, pp. 52–60, 2017, doi: 10.5815/IJITCS.2017.05.07.
[11] E. Kocaguneli, T. Menzies, and E. Mendes, “Transfer learning in effort estimation,” Empir. Softw. Eng., vol. 20, no. 3, pp. 813–843, 2015, doi: 10.1007/S10664-014-9300-5.
[12] S. Kumari, R. . C, S. K, K. Selvi, T. A. Mohanaprakash, and C. Tamilselvi, “Optuna-Optimized Machine Learning Technique for Accurate Diabetes Prediction and Classification,” in 2024 4th International Conference on Sustainable Expert Systems (ICSES), IEEE, Oct. 2024, pp. 1478–1485. doi: 10.1109/ICSES63445.2024.10763036.
[13] B. W. Boehm, “Software Engineering Economics,” IEEE Trans. Softw. Eng., vol. SE-10, no. 1, pp. 4–21, Jan. 1984, doi: 10.1109/TSE.1984.5010193.
[14] B. Kitchenham and E. Mendes, “Why comparative effort prediction studies may be invalid,” in Proceedings of the 5th International Conference on Predictor Models in Software Engineering, New York, NY, USA: ACM, May 2009, pp. 1–5. doi: 10.1145/1540438.1540444.
[15] L. L. Minku and S. Hou, “Clustering Dycom,” in Proceedings of the 13th International Conference on Predictive Models and Data Analytics in Software Engineering, New York, NY, USA: ACM, Nov. 2017, pp. 12–21. doi: 10.1145/3127005.3127007.
[16] F. Ferrucci, E. Mendes, and F. Sarro, “Web effort estimation,” in Proceedings of the 8th International Conference on Predictive Models in Software Engineering, New York, NY, USA: ACM, Sep. 2012, pp. 29–38. doi: 10.1145/2365324.2365330.
[17] N. Papernot, M. Abadi, Ú. Erlingsson, I. Goodfellow, and K. Talwar, “Semi-supervised knowledge transfer for deep learning from private training data,” in International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/pdf?id=HkY2BZcee
[18] C. M. . Bishop, Pattern recognition and machine learning. Springer, 2016.
[19] S. J. Pan and Q. Yang, “A Survey on Transfer Learning,” IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010, doi: 10.1109/TKDE.2009.191.
[20] M. C. Weiss et al., “The physiology and habitat of the last universal common ancestor,” Nat. Microbiol., vol. 1, no. 9, p. 16116, Jul. 2016, doi: 10.1038/nmicrobiol.2016.116.
[21] S. Tariq, M. Usman, R. Wong, Y. Zhuang, and S. Fong, “On Learning Software Effort Estimation,” in 2015 3rd International Symposium on Computational and Business Intelligence (ISCBI), IEEE, Dec. 2015, pp. 79–84. doi: 10.1109/ISCBI.2015.21.
[22] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?,” Nov. 2014.
[23] C. Zhuang et al., “Unsupervised neural network models of the ventral visual stream,” Proc. Natl. Acad. Sci., vol. 118, no. 3, Jan. 2021, doi: 10.1073/pnas.2014196118.
[24] M. Abadi et al., “Deep learning with differential privacy,” Commun. ACM, vol. 65, no. 10, pp. 61–71, 2022, doi: 10.1145/3549522.
[25] J. Chung and J. Teo, “Single classifier vs. ensemble machine learning approaches for mental health prediction,” Brain Informatics, vol. 10, no. 1, pp. 1–10, 2023, doi: 10.1186/s40708-022-00180-6.
[26] C. Tan, F. Sun, T. Kong, W. Zhang, C. Yang, and C. Liu, “A Survey on Deep Transfer Learning,” Aug. 2018.
[27] A. S. Razavian, H. Azizpour, J. Sullivan, and S. Carlsson, “CNN Features off-the-shelf: an Astounding Baseline for Recognition,” May 2014.
[28] T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A Next-generation Hyperparameter Optimization Framework,” arXiv: Learning. 2019.
[29] Optuna developers, “Optuna documentation.” Accessed: Nov. 29, 2023. [Online]. Available: https://optuna.readthedocs.io/
[30] B. Kiran Kumar, M. Rekha Sundari, and A. Surekha, “A Deep Learning-Based Technique for Evaluation of Estimation in Software Development,” 2024, pp. 291–306. doi: 10.1007/978-981-97-6995-7_22.
[31] J. W. Osborne, “Improving your data transformations: Applying the Box-Cox transformation,” Pract. Assessment, Res. Eval., vol. 15, no. 12, 2010.
[32] A. Dorado et al., “A Process Mining-Based System For The Analysis and Prediction of Software Development Workflows,” Oct. 2025.
[33] C. Hu et al., “Scalable imaging-free spatial genomics through computational reconstruction.” Aug. 07, 2024. doi: 10.1101/2024.08.05.606465.
[34] & J. K. Kuhn M., “Feature Engineering and Selection: A Practical Approach for Predictive Models.,” Chapman Hall, 2020.
[35] P. A. Whigham, C. A. Owen, and S. G. MacDonell, “A Baseline Model for Software Effort Estimation,” arXiv Softw. Eng., 2021, doi: 10.1145/2738037.
[36] Y. Assefa, F. Berhanu, A. Tilahun, and E. Alemneh, “Software Effort Estimation using Machine learning Algorithm,” in 2022 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), IEEE, Nov. 2022, pp. 163–168. doi: 10.1109/ICT4DA56482.2022.9971209.
[37] E. I. Mustafa and R. Osman, “SEERA: a software cost estimation dataset for constrained environments,” in Proceedings of the 16th ACM International Conference on Predictive Models and Data Analytics in Software Engineering, New York, NY, USA: ACM, Nov. 2020, pp. 61–70. doi: 10.1145/3416508.3417119.
[38] Adnan Purwanto,Lindung Parningotan Manik, “Software Effort Estimation Using Logarithmic Fuzzy Preference Programming and Least Squares Support Vector Machines.pdf,” Sci. J. Informatics, vol. 10, no. 1, pp. 1–12, 2023, [Online]. Available: https://pdfs.semanticscholar.org/db16/8396ba9c085705ea2df94f6d08e64435eb91.pdf
[39] L. P. Manik, “Features Engineering with Generating Genetic Algorithm for Software Effort Estimation,” Jan. 2022, doi: 10.24507/icicelb.13.01.1.
[40] H. R. Moechtar, S. Sulistyo, and R. Ferdiana, “A Review on Improving the Accuracy of Effort Estimation in Software Development with Agile Method,” in 2024 11th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), 2024, pp. 31–36. doi: 10.1109/ICITACEE62763.2024.10761956.
[41] L. Cao, “Estimating Efforts for Various Activities in Agile Software Development: An Empirical Study,” IEEE Access, vol. 10, pp. 83311–83321, 2022, doi: 10.1109/ACCESS.2022.3196923.
[42] S. Wakurdekar, S. Vanjale, P. Paygude, M. D. Gayakwad, A. Kadam, and R. Joshi, “Novel Approach to Design a Model for Software Effort Estimation Using Linear Regression,” J. Electr. Syst., 2024, doi: 10.52783/jes.1997.
[43] M. Awais and A. A. Malik, “A Comparative Analysis of Popular Software Effort Estimation Techniques,” in 2023 International Conference on IT and Industrial Technologies (ICIT), IEEE, Oct. 2023, pp. 1–5. doi: 10.1109/ICIT59216.2023.10335868.
[44] Z. P. A. P. S. HUYNH THAI HOC,RADEK SILHAVY, “Comparing Stacking Ensemble and Deep Learning for Software Project Effort Estimation,” IEEE Access, vol. 11, pp. 60590–60604, 2023, doi: 10.1109/access.2023.3286372.
[45] S. Amasaki, “Augmenting Window Contents with Transfer Learning for Effort Estimation.,” in CEUR Workshop Proceedings, 2020, pp. 4–12.
[46] B. Setiawan and A. Subekti, “Multi View Natural Network for Cross- Project Software Defect Prediction,” no. April, pp. 41–53, 2025, doi: 10.52985/insyst.v7i1.436.
[47] A. S. Kirso, “ENSEMBLE AND VOTING APPROACHES FOR DEFECT PREDICTION Universitas Nusa Mandiri Cross project defect prediction ( CPDP ) has emerged as a critical area within software engineering , offering a promising approach for enhancing software quality and maintainab,” MUST J. Math. Educ. Sci. Technol., vol. 10, no. 1, pp. 58–67, 2025.
[48] S. S. Ali, J. Ren, and J. Wu, “Framework to improve software effort estimation accuracy using novel ensemble rule,” J. King Saud Univ. - Comput. Inf. Sci., vol. 36, no. 9, p. 102189, Nov. 2024, doi: 10.1016/j.jksuci.2024.102189.
[49] K. Korenaga, A. Monden, and Z. Yucel, “Data Smoothing for Software Effort Estimation,” in 2019 20th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), IEEE, Jul. 2019, pp. 501–506. doi: 10.1109/SNPD.2019.8935841.
[50] S. S. Gautam and V. Singh, “Adaptive Discretization Using Golden Section to Aid Outlier Detection for Software Development Effort Estimation,” IEEE Access, vol. 10, pp. 90369–90387, 2022, doi: 10.1109/ACCESS.2022.3200149.
[51] I. Myrtveit, E. Stensrud, and U. H. Olsson, “Analyzing data sets with missing data: an empirical evaluation of imputation methods and likelihood-based methods,” IEEE Trans. Softw. Eng., vol. 27, no. 11, pp. 999–1013, 2001, doi: 10.1109/32.965340.
[52] B. Twala and M. Cartwright, “Ensemble missing data techniques for software effort prediction,” Intell. Data Anal., vol. 14, no. 3, pp. 299–331, May 2010, doi: 10.3233/IDA-2010-0423.
Kiriman Terbaru
-

26 Jul 2026
-

26 Jul 2026
-

24 Jul 2026
-

24 Jul 2026
-

24 Jul 2026